Zoltan Toth1
Environmental Modeling Center, NCEP
Acknowledgements:
Yuejian Zhu1 EMC
http://sgi62.wwb.noaa.gov:8080/ens/enshome.html
Eugenia Kalnay 91-96 20 1
Zoltan Toth 91-00 80 7 +2
Yuejian Zhu 95-00 40 2.5
Richard Wobus 96-00 50 2.5
Timothy Marchok 96-98 20 0.5
Istvan Szunyogh 99-00 50 1 +2
Steve Tracton 92-96 20 1
TOTAL: 15.5 personyear, 1.5 person over 10 yrs
Stephane Vannitsem Brussel, RMI
Jon Ahlquist Tallahassee, FSU
Leonard Smith Oxford, Univ. Oxford
Jeff Whitaker Boulder, NOAA/CDC - CIRES
Warren Tennant Pretoria, SAWB
Craig Bishop State College, PSU
Ron Gelaro Monterey, NRL
Kerry Emanuel Boston, MIT
Chris Snyder Boulder, NCAR
Marty Ralph Boulder, NOAA/ETL
2) Based on single control forecast
+ past verification statistics
+ MOS or other techniques
3) Based on ensemble of NWP fcsts

ESTIMATING ANALYSIS UNCERTAINTY:
In future -
Advanced assimilation techniques (eg, Kalman filter)
=>
With perfect 4DVAR,
errors are mostly the leading
LLVs (bred vectors)
Pires, Vautard & Talagrand,
1995
At present -
FAST GROWING errors can be estimated via breeding
Toth and Kalnay, 1993
Is rest of spectrum relevant? - Houtekamer
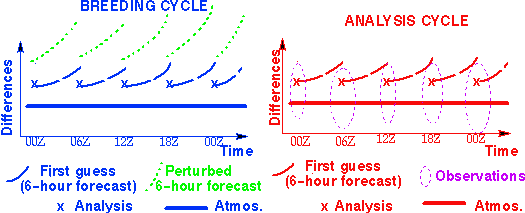
In breeding, perturbed forecasts
and rescaling
mimics the impact of observations
on analysis -
Dynamically fastest growing perturbations in analysis cycle
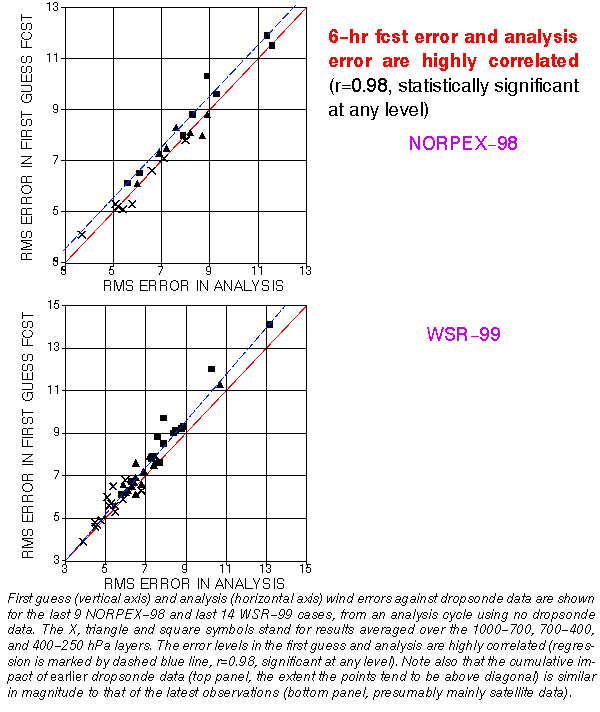
ANALYSIS ERRORS VS. BRED VECTORS (Iyengar et al, Poster)
1) Correlate well in a statistical sense (0.8 in
vertical)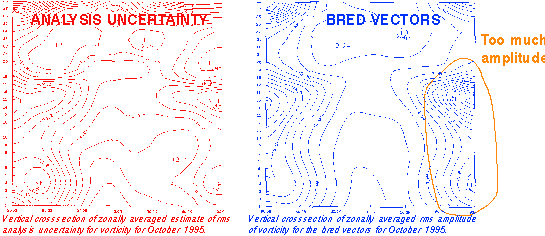
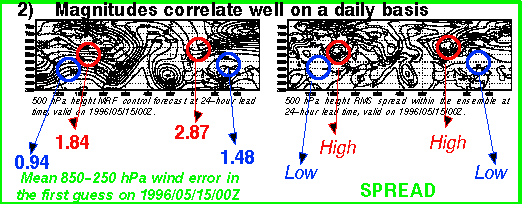
3) Sizable projection on each other on daily basis
Bred vectors are present as anal. errors (60,000 obs used
- But there are other errors as well =>
How to sample analysis errors?
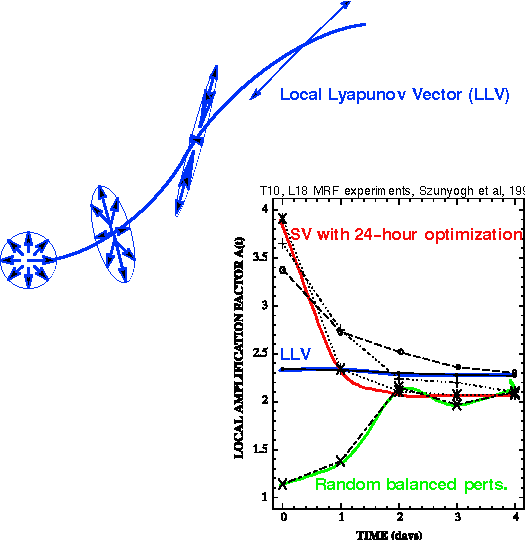
Extension of Lyapunov concept into nonlinear domain - Boffetta
Combination of naturally fastest growing nonlinear perturbations
Characteristics:
Cheap to generate
No optimization - Not optimal for any specific problem -
Can be used to give general solution?
Is nonmodal behavior important?
Are decaying/trailing LLVs important?
Norm not critical in definition
More representative of physical system?
Nonlinear features - No need for tangent linear model/approach
Can they be uniquely defined?
For complex systems, not even linear LLVs may be unique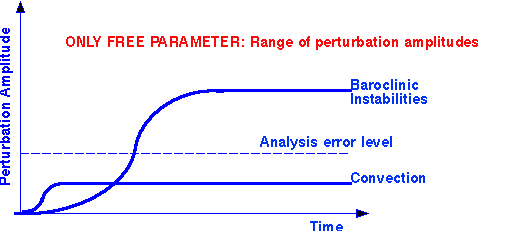
3) Arguments from both sides -
WHICH APPROACH IS MORE APPLICABLE IN
ENSEMBLE FCSTING AND TARGETING?
2) SAMPLING ANALYSIS ERRORS
SAMPLING ANALYSIS ERRORS:
1) BREEDING (NCEP, FNMOC, JMA)
Random sampling in subspace of fastest growing possible
anal. errors
2) MULTIPLE ANALYSIS CYCLES (CMC)
Random sampling in FULL space of possible analysis errors
(including neutral/decaying errors) => Serious overrepresentation of selected
decaying errors ("noise") Bishop, 2000
3) SINGULAR VECTORS (ECMWF):
Theoretically good approach. Must use analysis error covariance info
Potential problems:
a) Current applications do not constrain solutions by analysis error covariance info (instead use Total Energy, inappropriate)
b) Very expensive. If using anal. cov. info, order of magnitude more cpu need than for running ensemble fcsts themselves at same resol.
c) Solve separate problem for each application?
Separate ensembles for day 3, 4, 5,...? Not practical
d) How much do we gain compared to random sampling (breeding)?
Possibly not much Yoden et al., 1999
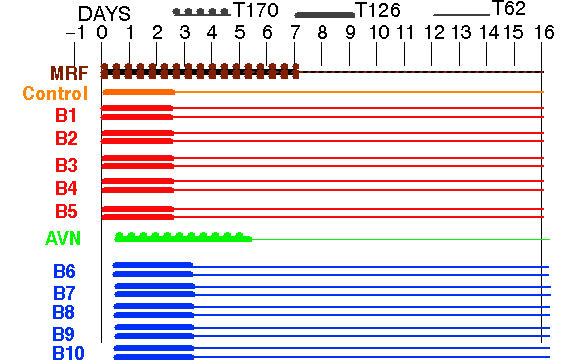
INCREASED MEMBERSHIP:
Add 6 perturbed forecasts at 1200 UTC
INCREASED HORIZONTAL RESOLUTION:
From T62 to T126 for first 60 hrs for all members
3 times CPU increase well within 5-fold increase in capabilities -
Ensembles are ideal for parallel computing!
Acknowledgements to: M. Brown, D. Michaud, J. Irwin, others
Need more CPU resources to remain competitive
NCEP ECMWF
1994 14 members, T62 32 members, T62
2000 20 members, T126 for 60 hrs 50 members, T159
2001, plan 40 members, T126 for 180 hrs 50 members, T255
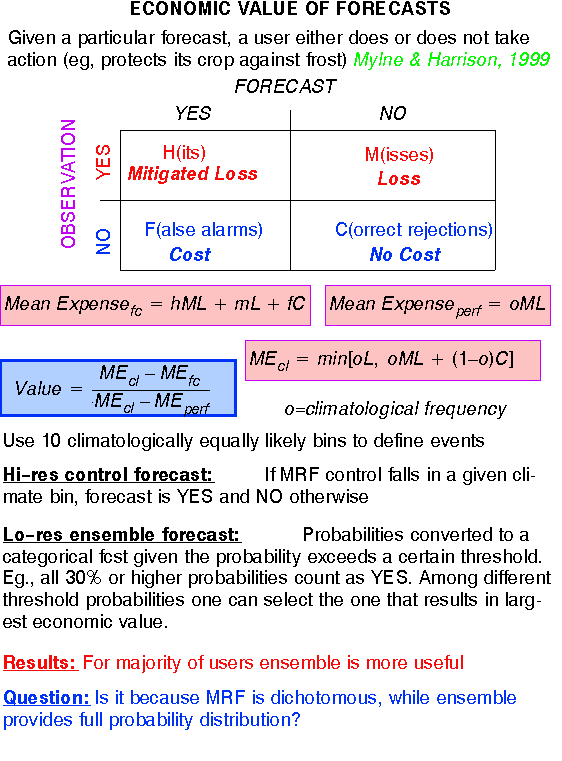
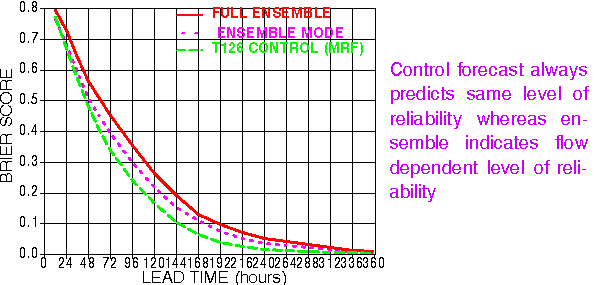
1) EXPECTED FCST VALUE:
a) Ensemble mean
Flow dependent filtering (time mean not needed now)
b) Ensemble mode -
Most likely scenario
2) FORECAST RELIABILITY:

a) Spaghetti diagrams
Show possible scenarios
b) Ensemble spread -
Degree of agreement
c) Normalized spread
Influence of Season/Region/Lead time removed
d) Relative measure of predictability
Shows higher/lower than average predictability
(influence of climate distribution also removed)
e) Probabilistic forecasts
PQPF, etc
OSO, NCEP ftp servers
2) GRAPHICAL PRODUCTS:
a) Gif (Web):
http://sgi62.wwb.noaa.gov:8080/ens/enshome.html
b) GEMPAK: NCEP centers?
c) Redbook: AWIPS
HPC, CPC, TPC, others?
2) NWS fcst offices:
WFOs in different regions -
What's needed for more systematic use? AWIPS???
2) Other agencies:
USAF
3) Private companies:
Energy, insurance, etc. industries
4) International:
Public and private users from Central- and South America, Africa, Europe, New Zealand
1) TRADITIONAL MEASURES:
Categorical fcsts: Average hit rate for modus
Point fcsts: Error in expected value, median, etc
(RMS, Pattern Anomaly Correlation)
2) DISTRIBUTIONAL MEASURES:
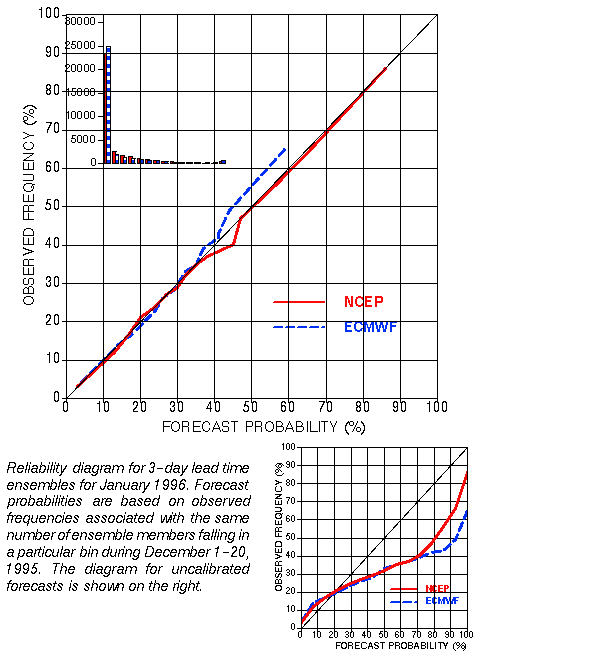
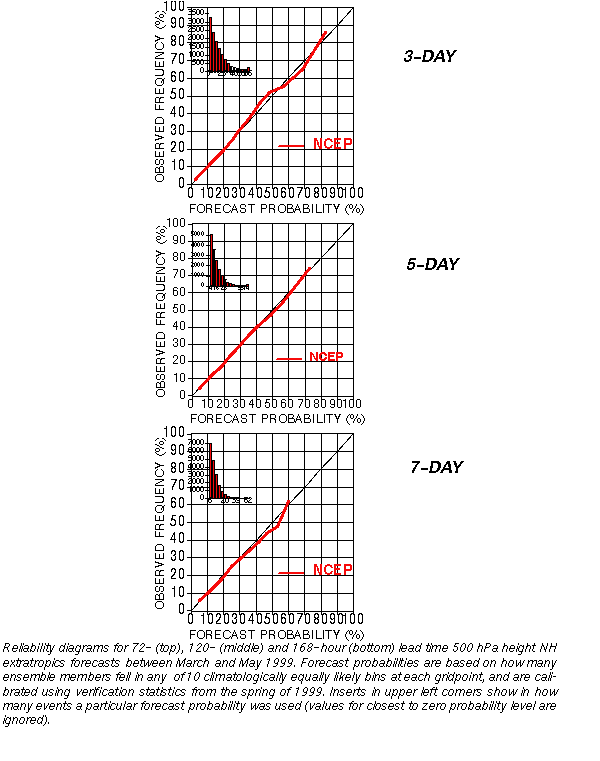
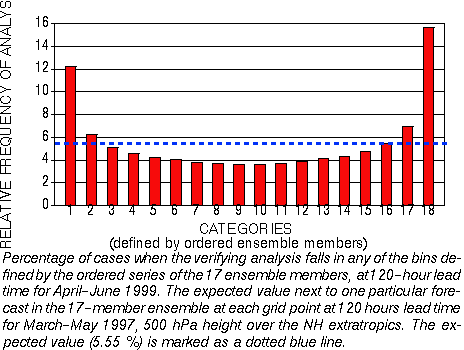
a) Talagrand (Verification Rank) diagram
- measures consistency only
b) Reliability diagrams
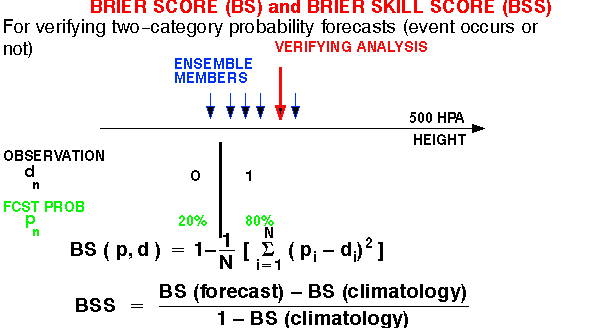
c) Brier Skill Score
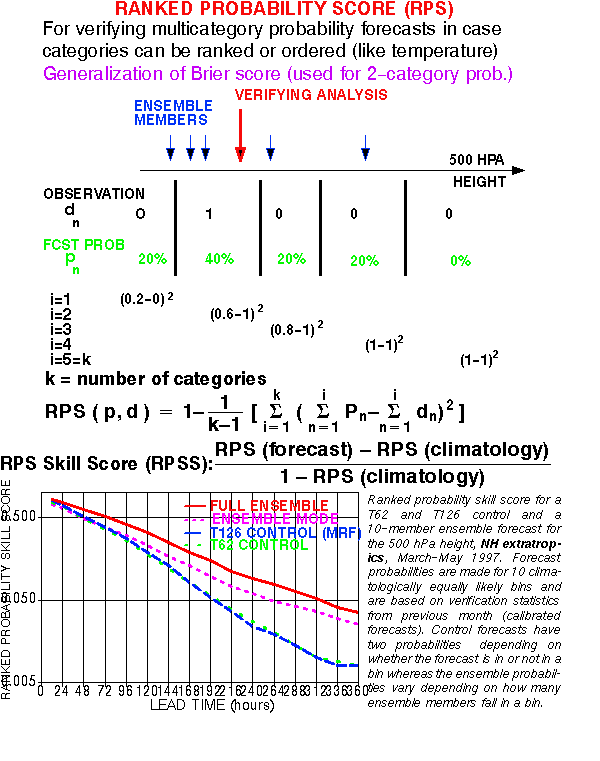
d) Ranked Probability Skill Score
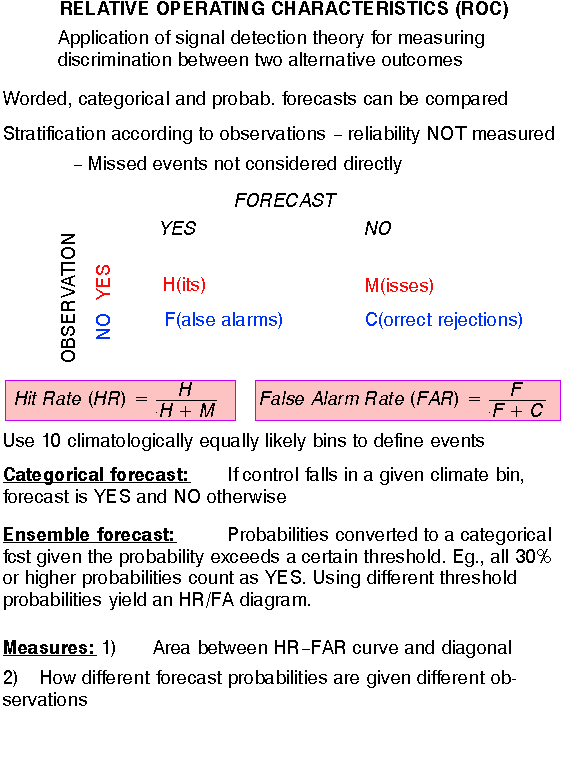
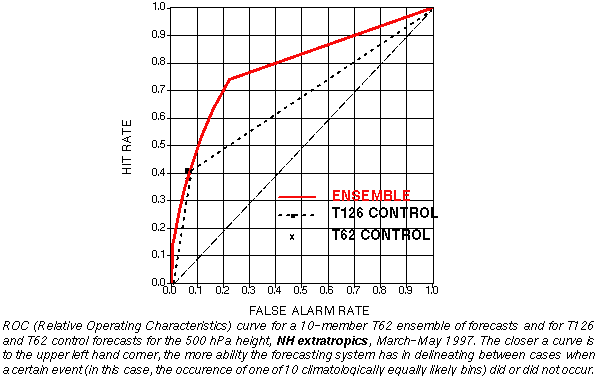
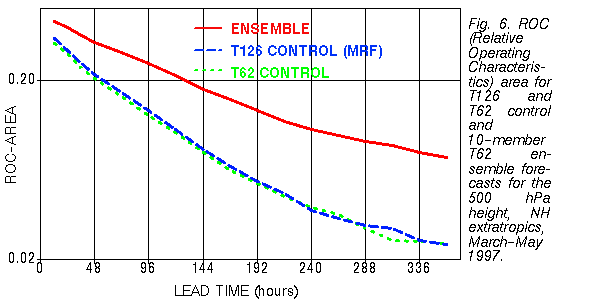
e) Relative Operating Characteristics
f) Information content
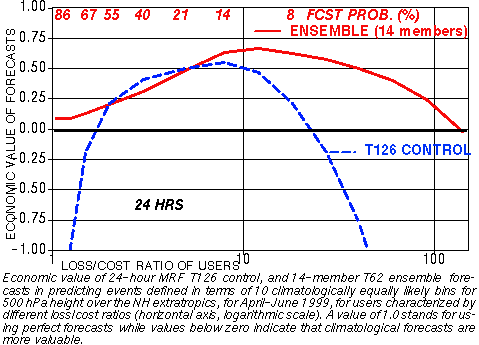
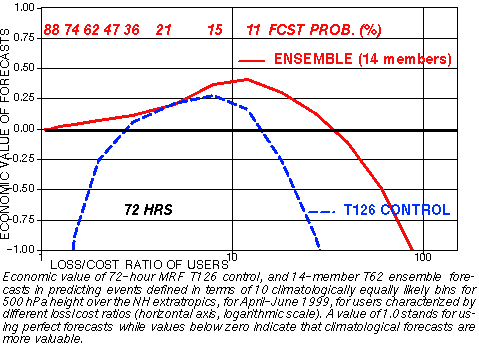
g) Economic Value
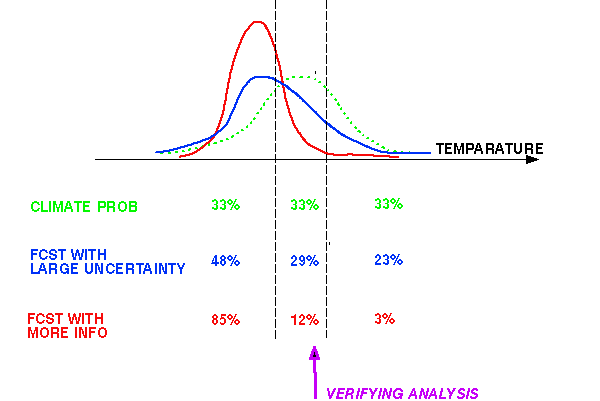
1) Must be "sharp", have lots of information wrt climatology
(called RESOLUTION)
A N D
2) Must be consistent with observations
(called RELIABILITY)
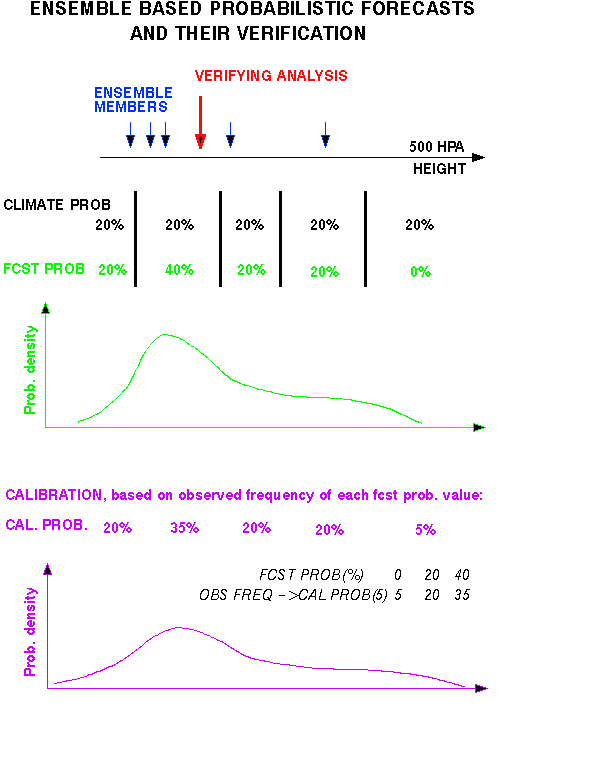
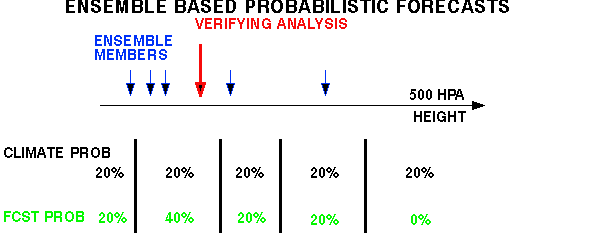
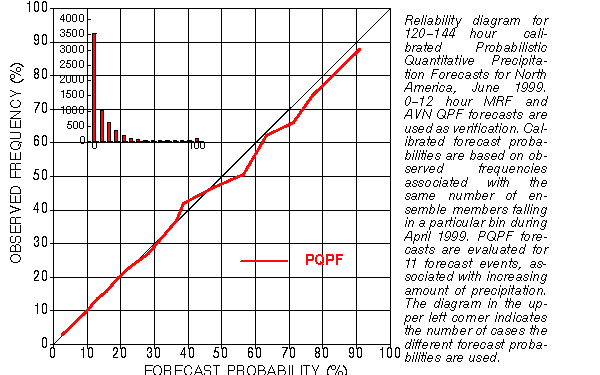
2) PROBABILITIES: In framework of 10 climate bins
CONTROL ENSEMBLE
Yes or No fcst for an event Full probability distribution
"UPGRADE" control: "DOWNGRADE" ensemble:
Based on past verification, Take probability at mode
(Pm),
can be calibrated (like ens.) distribute (1-Pm)
over 9 other b

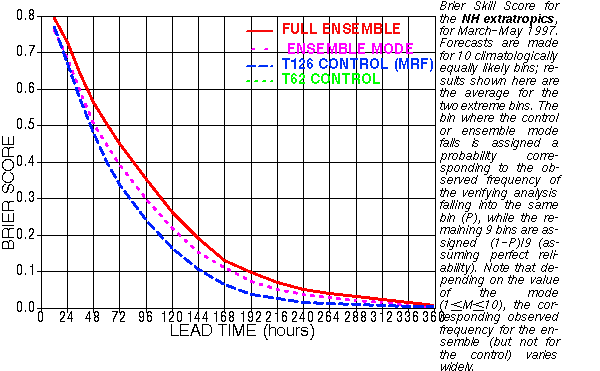
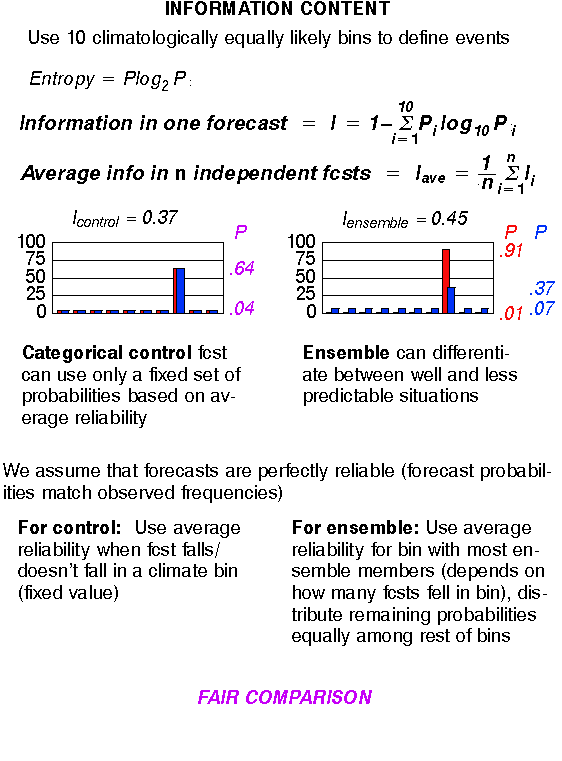
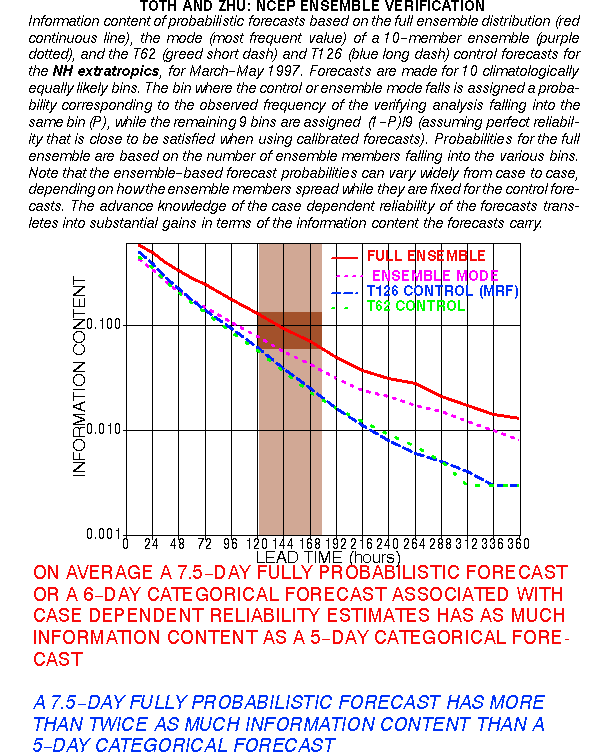
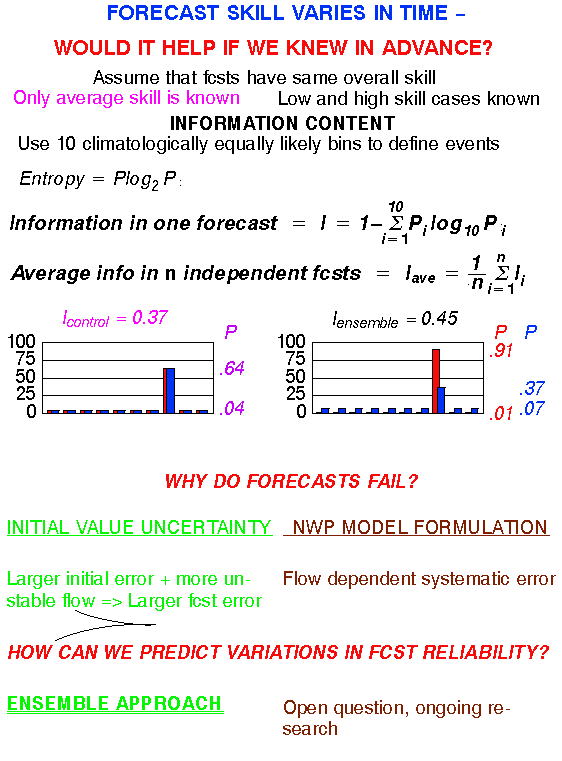
What are the typical variations in foreseeable forecast uncertainty?
What variations in predictability can the ensemble resolve?
METHOD:
Ensemble mode value to distinguish high/low predictability cases
Stratify cases according to ensemble mode value -
Use 10-15% of cases when ensemble is highest/loewest
DATA:
NCEP 500 hPa NH extratropical ensemble fcsts for March-May 1997
14 perturbed fcsts and high resolution control
VERIFICATION:
Hit rate for ensemble mode and hires control fcst
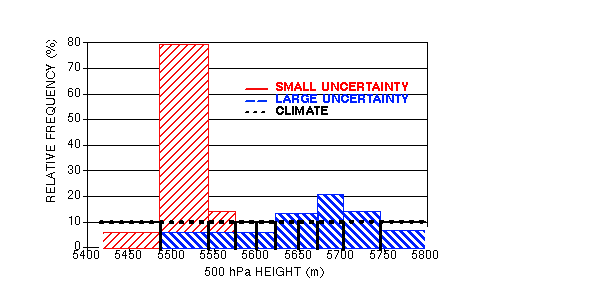
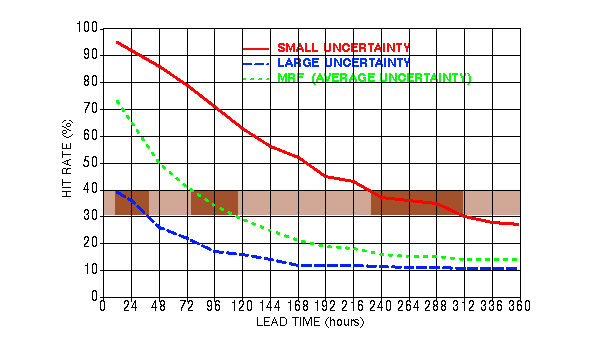
THE UNCERTAINTY OF FCSTS CAN BE QUANTIFIED IN ADVANCE
HIT RATES FOR 1-DAY FCSTS
CAN BE AS LOW AS 36%, OR AS HIGH AS 92%
10-15% OF THE TIME A 12-DAY FCST CAN BE AS GOOD, OR A 1-DAY FCST CAN BE AS POOR AS AN AVERAGE 4-DAY FCAST
1-2% OF ALL DAYS THE 12-DAY FCST CAN BE MADE WITH MORE CONFIDENCE THAN THE 1-DAY FCST
AVERAGE HIT RATE FOR EXTENDED-RANGE FCSTS IS LOW - VALUE IS IN KNOWING WHEN FCST IS RELIABLE
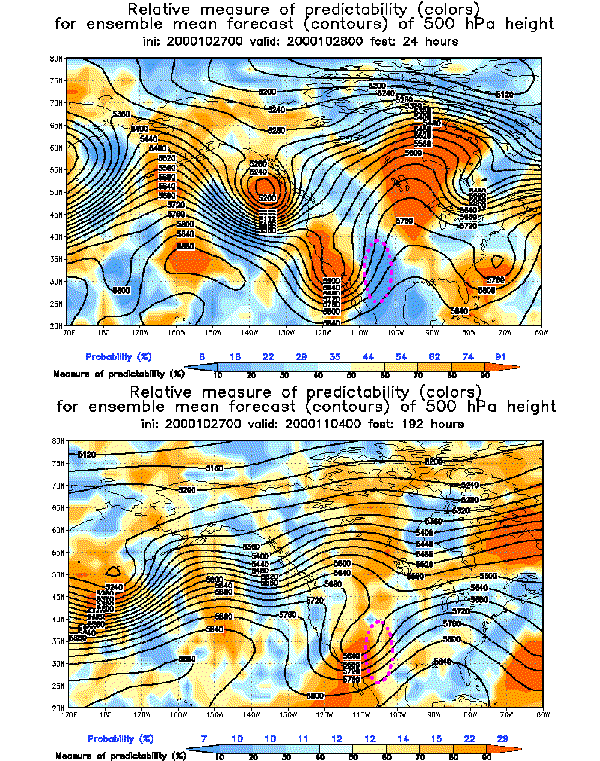
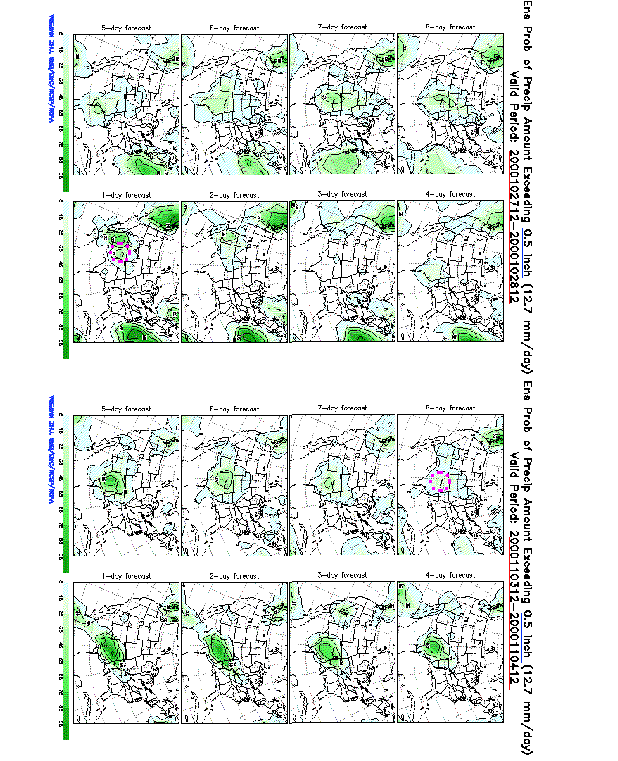
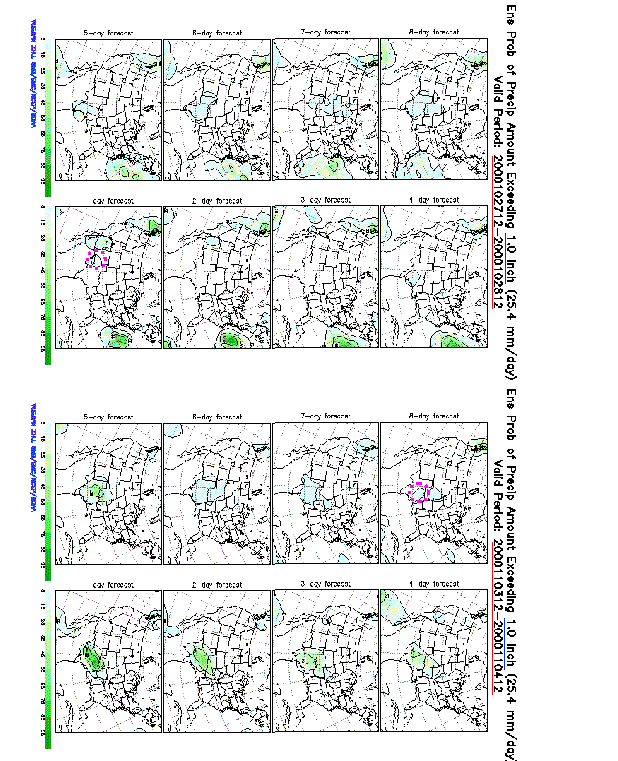
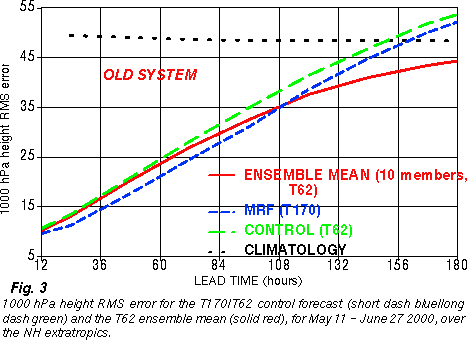
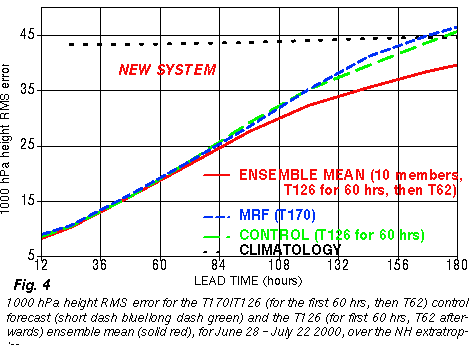
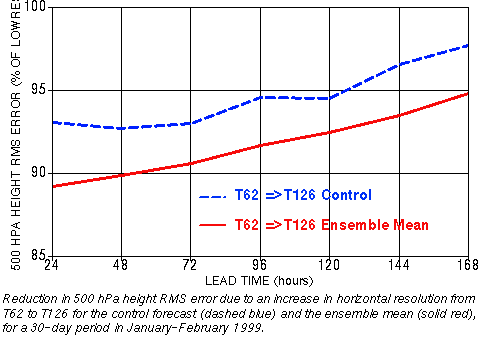
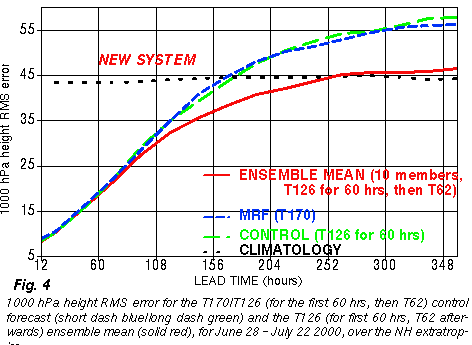
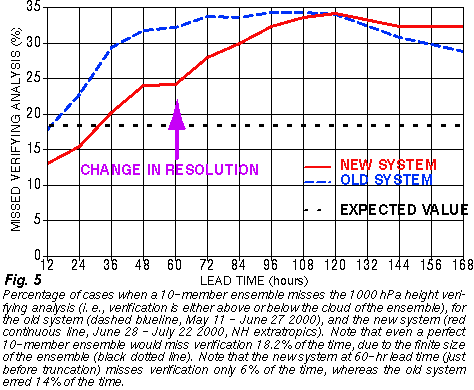
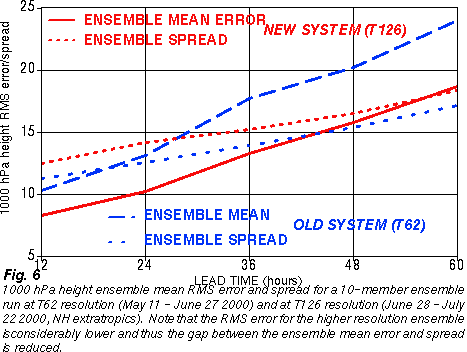
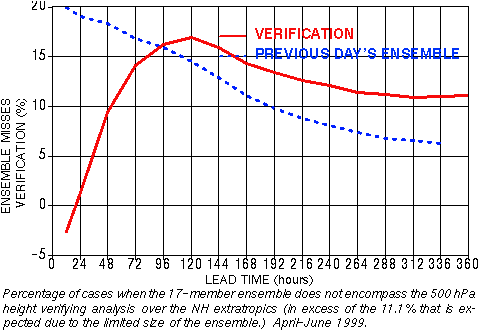
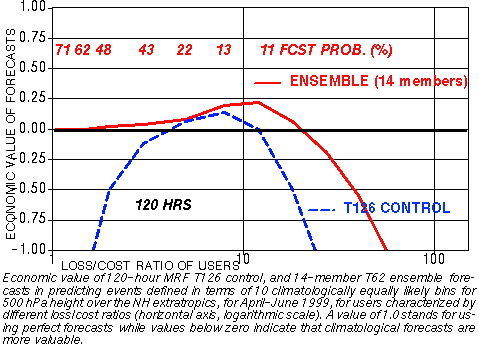
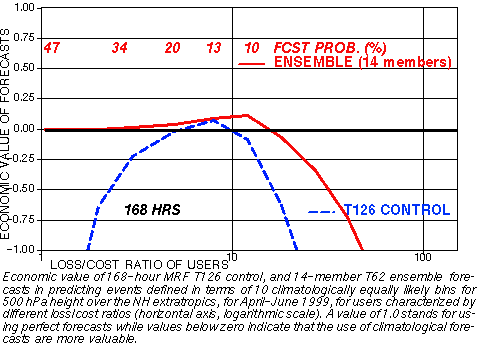
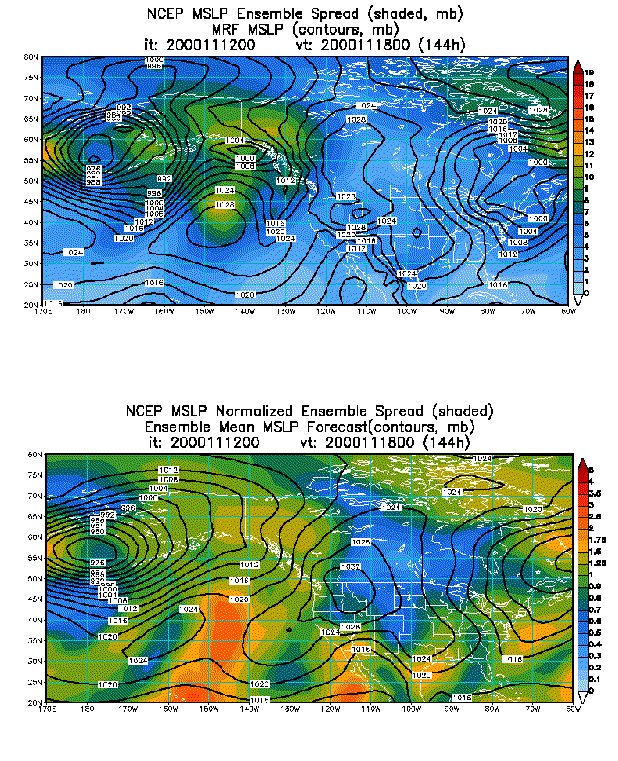
2) Improved analysis schemes
- within 6 years:
10% 5D AC improvement, 12-hr gain
3) Better fcst models
4) Use of ensembles: 25-30% 5D Brier score imprvm.,24-hour gain
CONTROL
ENSEMBLE
Yes or No fcst for an event Full probability distribution
Initial condition
Boundary condition Missing/poor model for boundary
Missing/poor model for boundary
Imperfect model Resol., approx. in physics, etc.
Attribution of error is very difficult (e. g., snow storm of 000125)
- ambitious goal
Ensemble fcsts as diagnostic tool to identify systematic model error
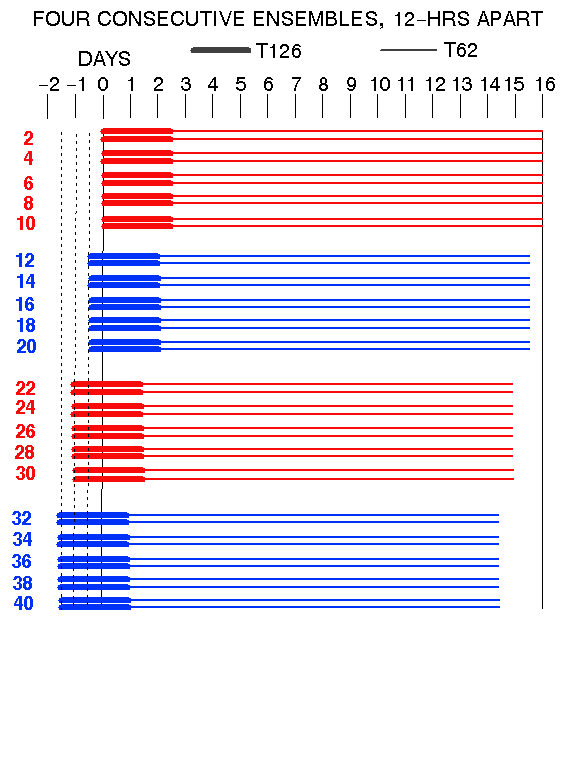
Setup: Use consecutive ensembles
Mark areas where cloud of all fcsts misses verifying analysis
Measure normalized distance of ens mean from analysis
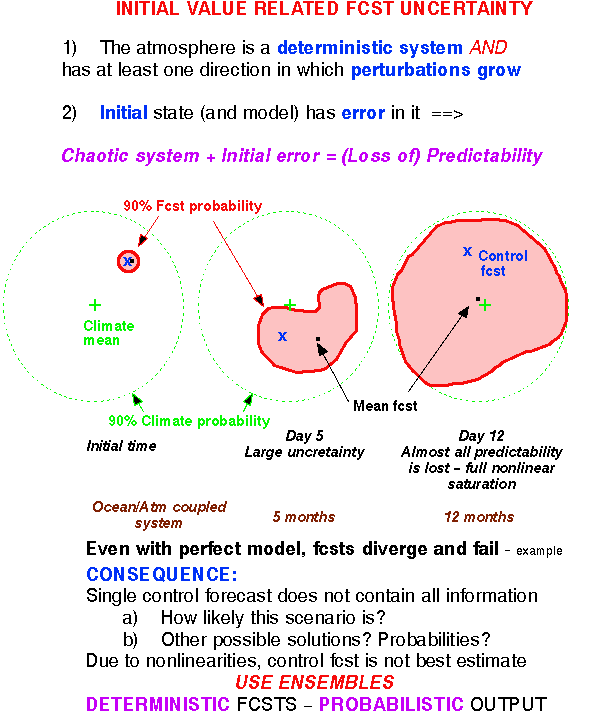
Model (and ensemble formation) is perfect =>
Each member equally likely
Verifying analysis is indistinguishable from members =>
Each interval between ordered members equally likely,
inclulding open ended extreme intervals

N-member ensemble defines N+1 intervals -
Chance of verif. analysis falling outside of ensemble: 2/N+1
Probability that four 10-member independent ensembles miss verific.:
P=(2/11)*(1/11)**3 = 0.0001366026
But analysis errors may be temporally correlated -
Assumption 2:
Analysis errors are independent only every 24 hrs (every 4th)
Probability that two 20-member independent ensembles miss verific.:
P=(2/21)*(1/21)=0.0045
NH extratropics: K=3456 gridpoints:
Expected number of outliers for 4 consecutive ensembles: K*P = 17
8 consecutive ensembles: K*P=0.035
If significantly more outliers =>
PERFECT MODEL ASSUMPTION DOES NOT HOLD
2) Areas where 8-12-16 consecutive ensembles fail
CAN THESE ERRORS BE INITIAL VALUE RELATED? NO?
a) These errors develop and travel slowly with synoptic system
(Unlike initial value related error that travels faster)
b) Errors in initial condit. for a system with various fcst lead times
are from widely different geographical areas =>
VERY UNLIKELY THAT SAME (pos. or neg.) ANALYSIS ERROR IS
PRESENT AT NUMEROUS TIMES AND PLACES
FURTHER ISSUES
Qualitative results - only areas defined (though highly significant)
Can error estimates be quantified?
Comparison with HPC subjective model bias evaluation?
(Initial & model errors mixed?)
Vis5D application? What variable/level problem shows up first?
20000125 snow storm Strong indication for model error (T62 ens)
Model development - Identify problem areas
Test model on significant cases in ens mode
Ensemble development -
Perturb model during integration to represent
remaining model related uncertainty
Analysis - Compare ens. cloud at various lead times w. obs.
to recognize areas of model error?
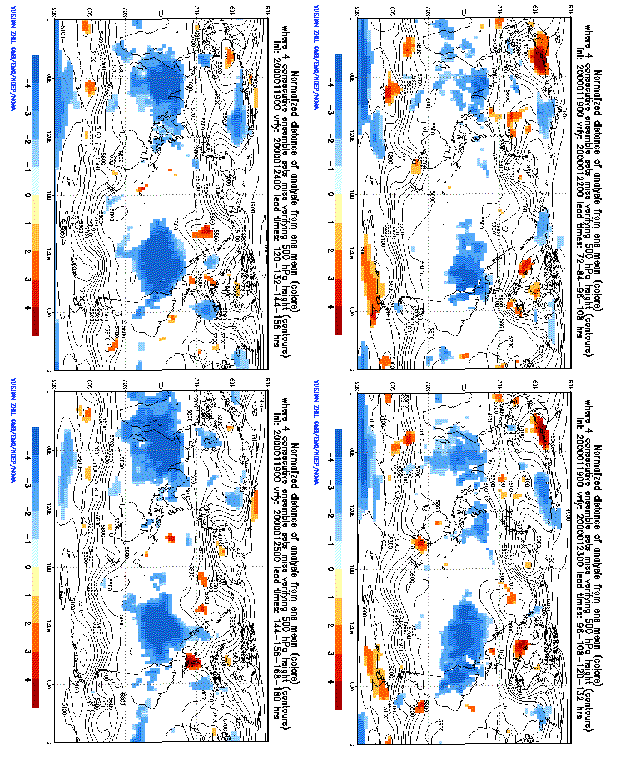
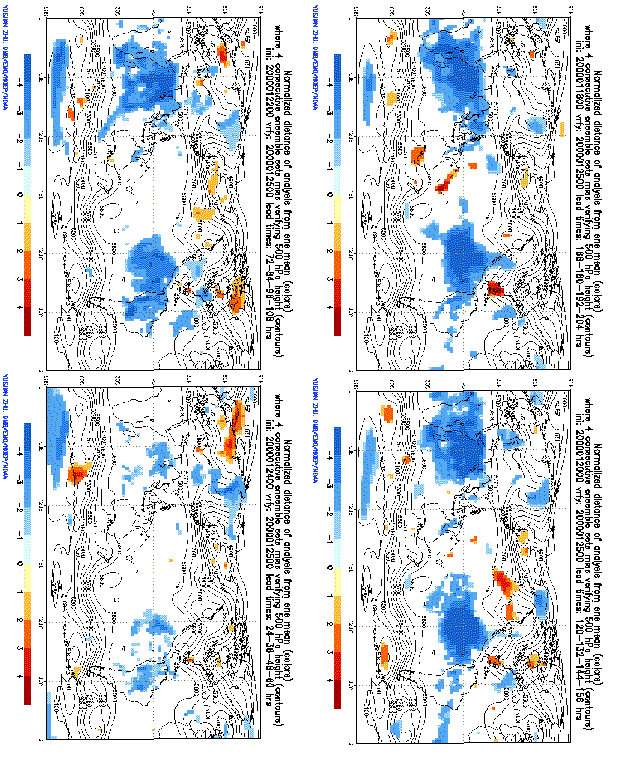
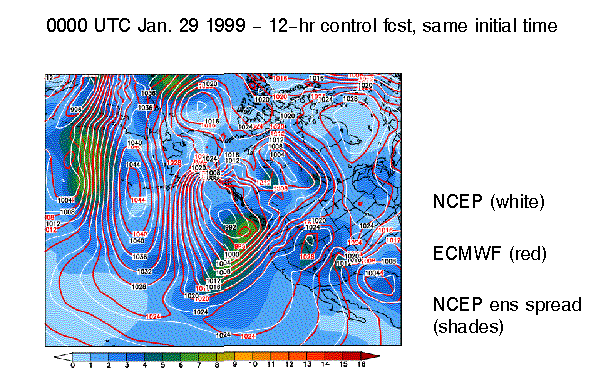
12-hr fcsts can have MORE UNCERTAINTY than 9-day fcsts
Daily extended range weather prediction:
Possible in LOW UNCERTAINTY cases
If variations in hit rates due to model error could be foreseen:
RESOLUTION WOULD INCREASE
Most observations are taken at fixed times or as opportunities arise
ADAPTIVE APPROACH:
Some observations taken adaptively to maximize anal./fcst
impact
TARGETED OBSERVATIONS
IMPROVE PARTICULAR FCST FEATURE:
Eg, 3-day precip fcst over ne US
1) How to select fcst feature?
a) Uncertainty/information content in fcst
b) Societal impact: Is uncertainty tolerable?
2) How to identify sensitive
area to be observed?
(i) Adjoint sensitivity calcuations
(ii) Ensemble transform technique
3) How to take observations?
(i) Dropsondes released from manned aircraft
(ii) Unmanned aircraft
(iii) Balloons
(iv) Satellite
Bishop and Majumdar, 2000
Variance = uncertainty under standard
observational network
TRANSFORM ENSEMBLE
to see effect of extra observations
Variance = uncertainty with
extra obs. added at location X
MOVE X to see if variance at t2 optimally reduced at
Verif area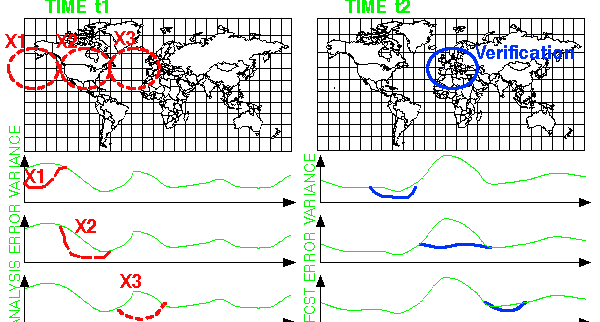
TRANSFORMATION:
Linear combination of ensemble perturbations -
SVD in vector space
of ensemble perturbations at t1 and t2
With 1st SV, VAR(V,t2)
VERY EFFICIENT
minimize VAR(GLOBTARG,t1)
NEW ELEMENT: Transition toward operations
EACH MISSION:
Requested by field/HPC forecasters to support critical
weather fcsts
Operational needs
Among predisigned flight tracks, best is selected objectively
SDM training
Dropsonde flight missions carried out by AOC & USAF Reserve
COLLABORATIVE EFFORT:
Regions => HPC => EMC/SDM
=> AOC/USAF Reserve
Forecast feature Sensitive area Aircraft operations
TOTAL OF 12 MISSIONS, 300 DROPSONDES:
5 NOAA G-lV (from Anchorage) and
10 USAF C-130 (from Honolulu) flights
ALL DATA USED OPERATIONALLY
DATA IMPACT EVALUATION:
Near real time parallel assimil. fcst cycle with
dropsonde data excluded:
http://sgi62.wwb.noaa.gov:8080/ens/target/wsr2000.html
PRIORITIZE
Objective guidance can be developed based on ensemble
EMC/SDM: Sensitivity computations for each event:
General guidance
Best flight tracks
Expected data impact
Based on results and priority of each event and available resources,
DECIDE WHETHER TO FLY, AND WITH WHICH PLANE(S)
Can be fully automated for other observing systems

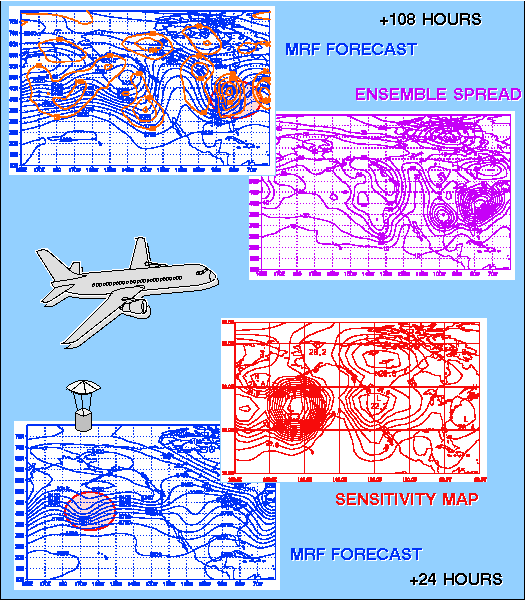
Eleventh AMS Conference on Numerical Weather Prediction
(August 19-23, 1996, Norfolk, VA) Preprint Volume Back Cover: Another
application of ensemble prediction is to identify where and when additional
observations can most effectively improve forecasts. Observing system platforms,
such as aircraft released dropwinsondes, can then be "targeted" to specific
regions where they will have maximum impact. Such a system is under active
investigation as a component in the North American Observing System (NAOS)
program (McPherson, invited talk; Lord, this volume), and in the North
Atlantic field experiment (FASTEX).
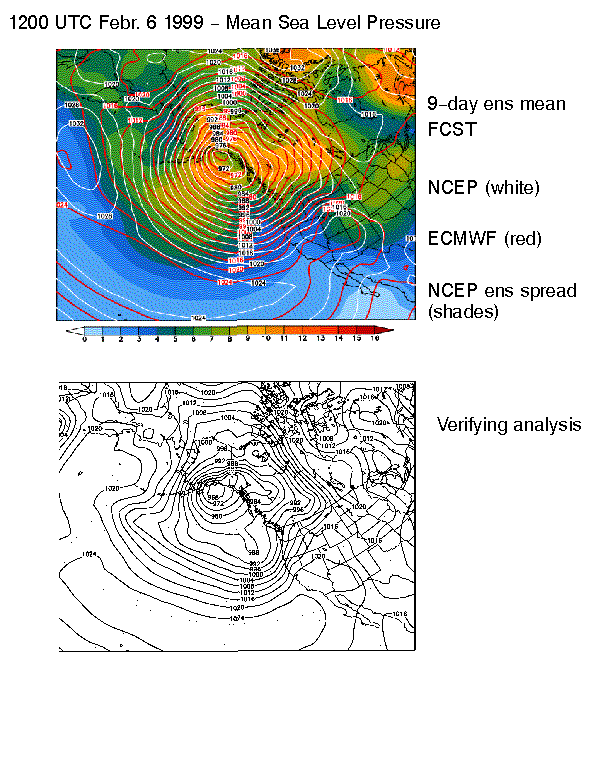
In the illustration, the NCEP MRF 4.5 days 500 hPa height
forecast, valid 1200 UTC 15 April 1996 (in blue, top left), displays an
intense trough over the eastern third of the U.S. The ensemble spread valid
at this time (top right) indicates considerable uncertainty and potential
for large errors with this system (that, in fact, occurred, see error field
in orange, top left panel). The evolution of this uncertainty can be traced
back to, for example, 24 hours after the initial time by an inexpensive
singular value decomposition procedure applied to the set of nonlinear
ensemble forecasts (Bishop and Toth, this volume). In this case the procedure
identifies a region in the east-central Pacific (minimum in bottom right
figure) which is associated with a trough in the 24-hour MRF prediction
(bottom left). It is this area in which targeted observations at that time
are expected to improve most the ensuing 3.5-day forecast over the eastern
U.S.
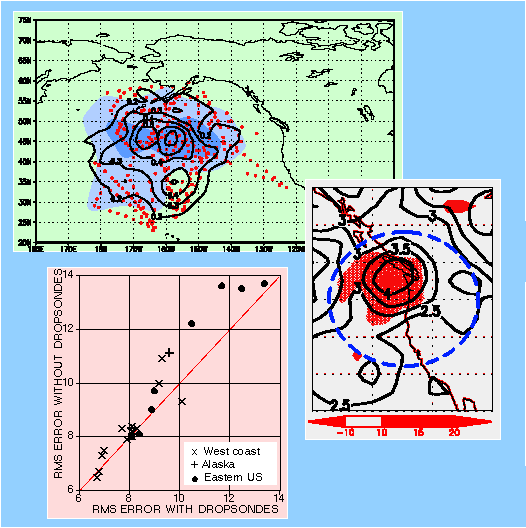 Fourth
Symposium on Integrated Observing Systems (January 10-14 2000, Long Beach,
CA) Preprint Volume Back Cover: Over the past few years targeted
observations, where data are taken in order to improve particular forecast
features, have been tested and become part of the observing system. During
January-February 1999 during the 15 missions of the quasi-operational Winter
Storm Reconnaissance program dropsonde observations were adaptively collected
over the northeast Pacific (top left panel, red dots) in areas that were
found sensitive to forecast errors developing downstream over the continental
US (shades of blue). Analysis/forecast cycles were run both with and without
the dropsonde data. The contour lines in the top panel show the average
difference between analyses with and without the use of the targeted data
for the surface pressure. The middle right panel shows the average location
of the verification regions (at 48-hour lead time) that were selected in
real time by operational forecasters, expecting the possible occurence
of severe weather associated with potentially large forecast errors (dashed
blue ellipsoid). The contour lines in the middle panel show the actaul
average surface pressure forecast error, indicating that the forecasters
identified well the forecast problem areas in advance. Also shown in this
panel is the average rms forecast error reduction (shades of red), indicating
that the impact of the data is where it was intended to be, within the
predefined verification region, over the area of maximum forecast errors.
The bottom left panel shows a scatterplot of rms wind errors (1000-250
hPa, measured against observations within the predefined verification regions)
for 25 forecasts with and without the use of the targeted data. Combined
verification statistics using wind, surface pressure and accumulated precipitation
indicate that in most (18 out of 25) cases the forecasts improved where
and when intended due to the use of the adaptive observations. The 10-20%
regional rms error reduction in the operationally most critical weather
situations is comparable to error reductions in the Northern Hamisphere
extratropical rms errors due to general improvements in data quality and
quantity over the past 25 years. (For further details, see Toth et al.,
this volume.)
Fourth
Symposium on Integrated Observing Systems (January 10-14 2000, Long Beach,
CA) Preprint Volume Back Cover: Over the past few years targeted
observations, where data are taken in order to improve particular forecast
features, have been tested and become part of the observing system. During
January-February 1999 during the 15 missions of the quasi-operational Winter
Storm Reconnaissance program dropsonde observations were adaptively collected
over the northeast Pacific (top left panel, red dots) in areas that were
found sensitive to forecast errors developing downstream over the continental
US (shades of blue). Analysis/forecast cycles were run both with and without
the dropsonde data. The contour lines in the top panel show the average
difference between analyses with and without the use of the targeted data
for the surface pressure. The middle right panel shows the average location
of the verification regions (at 48-hour lead time) that were selected in
real time by operational forecasters, expecting the possible occurence
of severe weather associated with potentially large forecast errors (dashed
blue ellipsoid). The contour lines in the middle panel show the actaul
average surface pressure forecast error, indicating that the forecasters
identified well the forecast problem areas in advance. Also shown in this
panel is the average rms forecast error reduction (shades of red), indicating
that the impact of the data is where it was intended to be, within the
predefined verification region, over the area of maximum forecast errors.
The bottom left panel shows a scatterplot of rms wind errors (1000-250
hPa, measured against observations within the predefined verification regions)
for 25 forecasts with and without the use of the targeted data. Combined
verification statistics using wind, surface pressure and accumulated precipitation
indicate that in most (18 out of 25) cases the forecasts improved where
and when intended due to the use of the adaptive observations. The 10-20%
regional rms error reduction in the operationally most critical weather
situations is comparable to error reductions in the Northern Hamisphere
extratropical rms errors due to general improvements in data quality and
quantity over the past 25 years. (For further details, see Toth et al.,
this volume.)
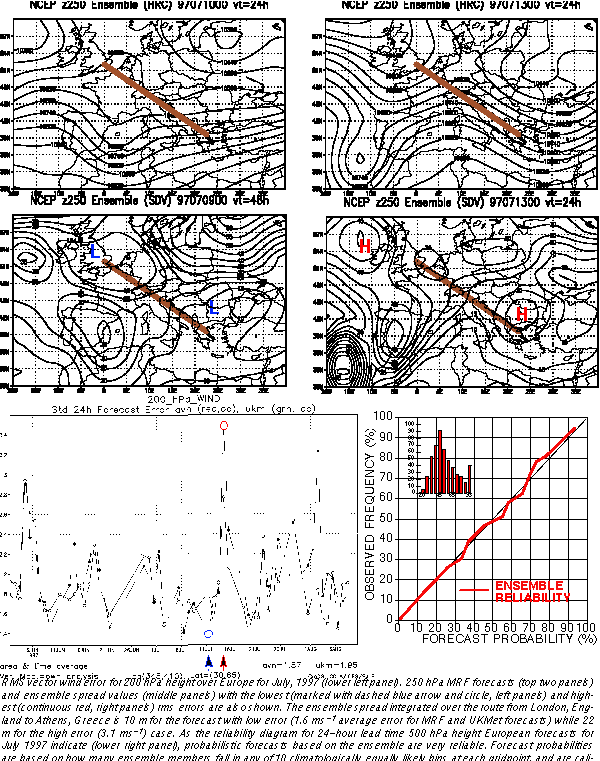
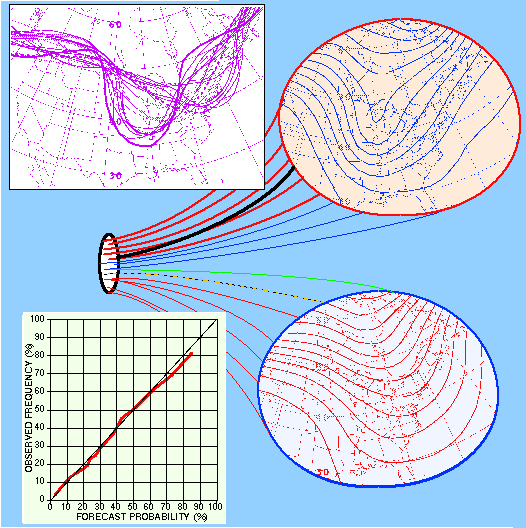 Eleventh
AMS Conference on Numerical Weather Prediction (August 19-23, 1996, Norfolk,
VA) Preprint Volume Front Cover: Over the past few years ensemble
forecating has become an important component of numerical weather prediction
and operational forecasting (Tracton et al., this volume). As an illustration,
the 5640 m single contour ("Spaghetti") diagram of the 500 hPa height is
shown at 4.5 days lead time (valid at 1200 UTC on October 20, 1995, top
left), displaying all the 17 members of the NCEP global ensemble (Kalnay
and Toth, this volume). The yellow dotted and solid green lines represent
the high resolution (T126) control forecasts (started on the 16th and 15th
at 0000 UTC and 1200 UTC, respectively), while the red and blue lines,
respectively, are the perturbed forecasts about the two controls. The verifying
analysis is shown as a heavy black line.
Eleventh
AMS Conference on Numerical Weather Prediction (August 19-23, 1996, Norfolk,
VA) Preprint Volume Front Cover: Over the past few years ensemble
forecating has become an important component of numerical weather prediction
and operational forecasting (Tracton et al., this volume). As an illustration,
the 5640 m single contour ("Spaghetti") diagram of the 500 hPa height is
shown at 4.5 days lead time (valid at 1200 UTC on October 20, 1995, top
left), displaying all the 17 members of the NCEP global ensemble (Kalnay
and Toth, this volume). The yellow dotted and solid green lines represent
the high resolution (T126) control forecasts (started on the 16th and 15th
at 0000 UTC and 1200 UTC, respectively), while the red and blue lines,
respectively, are the perturbed forecasts about the two controls. The verifying
analysis is shown as a heavy black line.
The central schematic illustrates the divergence of solutions as a
result of analysis uncertainties. Out of the 17 members, two dominant clusters
of 8 (top right) and 7 (bottom right, including the two controls) forecasts
were formed in this case, indicating the possibility of two distinctly
different flow patterns at day 4.5. The verification (heavy black line)
falls within the first cluster, which indicated a deeper and slower developing
trough than the controls alone would suggest. For additional synoptic examples
and other products derived from the ensemble, see Wobus et al. (this volume).
Probabilistic forecasts from the NCEP ensemble have demonstrated useful
resolution and sharpness, and are very reliable, as displayed for the 4.5
days 500 hPa NH extratropical height forecasts (bottom left). Probabilistic
forecasts (abscissa) are made for 10 climatologically equally likely bins
and then the relative occurrence of the verifying analysis in all bins
are accumulated as a condition of forecast probabilities (ordinate). The
ensemble based probabilistic forecasts for February 1996 were calibrated
using independent verification data from January 1996 (Zhu et al., this
volume).